

Courtesy the artist and Altman Siegel, San Francisco
Interviews
Trevor Paglen on Artificial Intelligence, UFOs, and Mind Control
The pioneering artist was one of the first to reckon with AI. Now he’s happy the rest of the world is catching up.

Long before the torrent of attention unleashed by ChatGPT’s public release in November 2022, the artist Trevor Paglen was patiently teaching us about the underlying technologies and training sets of artificial intelligence. He not only demonstrated how they interpret images—rendering them into data whose applications have severe social and moral consequences—but also unveiled what they are made of. Paglen’s art is about surveillance, technology, and hidden forms of power. But one could also say his work is about faith and doubt: It bolsters our faith that certain things we can’t see really do exist, and sows doubt about whether we consented to live in a society where certain things exist. CIA black sites and rendition programs. Spy satellites. Secret military bases. Machine-hallucinated images. Racist classification schemes fueling facial recognition systems. The surveillance of our everyday behaviors. UFOs.
Paglen deploys the camera less for depictive purposes than as an analogy for the extraordinary labor of making something visible—whether the thing to be seen is a surveillance drone, the computational analysis routinely performed on photographs of our faces, or a strategy of psychological warfare shaping our media consumption. Photography is neither his sole medium nor his raison d’être, but it’s indispensable to a practice that examines how belief is compelled.

Sarah M. Miller: You’ve interrogated the history, tools, and implications of AI for about twelve years, focusing particularly on systems that interpret images. How does it feel that the rest of the world is catching up to this topic—and is it too late?
Trevor Paglen: It’s not too late. I’m happy that the rest of the world is catching up, because it’s important to have other voices in these conversations. For a very long time, these conversations have been happening in computer science departments, in tech companies, and I think a lot of people from the humanities didn’t even know that there was this whole other mode of vision—seeing with machines—being developed and becoming a part of our everyday infrastructures. The theory of perception underlying so much of AI and computer vision is shockingly bad from a humanities perspective. It’s crucial for people with backgrounds outside the tech industry to look at these systems critically.
Miller: You often use the terms “computer vision” or “machine learning”—as opposed to “artificial intelligence”—to describe the subject of your research. What’s the difference?
Paglen: Computer vision has a long history, going back to the 1950s and ’60s, that overlaps with the development of digital photography, digital imaging, image processing, et cetera. And there are a bunch of pre–machine learning algorithms that are still in common use in computer vision. I generally try to use “computer vision” because I’m bracketing out stuff about language, and chatbots, and other kinds of optimization algorithms that fall under AI more generally.
The machine learning moment really starts around 2012, and it’s when people figure out that you can use neural networks, which had been invented a long time ago, to actually do stuff—as long as you have a whole bunch of training data and a whole bunch of computing power. Machine learning is the stuff that what we now call AI is made out of. But there have been different approaches to AI in the past that had nothing to do with machine learning at all—the dominance of the machine learning approach is relatively new, whereas AI has been around for a long time.
“Artificial intelligence” also doesn’t really mean anything, and it has a lot of ideological associations. It’s a term that lends itself to mystification.

Trevor Paglen, Image Operations. Op. 10, 2018. Single channel video projection, sound, 23 minutes
Miller: A lot of your work related to AI functions as tutorial—teaching viewers how computer vision works and what it’s built on. One of my favorites is Image Operations. Op. 10 (2018). Could you describe how you made that piece?
Paglen: It’s a video of musicians performing Debussy’s String Quartet in G minor, Op. 10. You’re watching the string quartet playing, you’re hearing the music, and your visual perspective gradually shifts from that of a camera to that of various computer vision and AI algorithms, which are interpreting the performers and their actions—the machinic eyes of algorithms that are designed to estimate age, gender, ethnicity, emotional states, gestures. So you’re getting a sense of the different ways that humans have developed to try to have computers make sense of images.
We built a programming language in my studio to work with computer vision tools, and to turn their algorithmic abstractions back into images. I looked at different kinds of media and images to find the thing that I felt contrasted most with the machinic ways of seeing. Instrumental music performance—that’s almost pure affective excess, fundamentally not quantifiable. So that’s the juxtaposition I set up in that piece.
Miller: It’s amazing to watch the analytics take place in real time. It makes you understand that the calculations about who these people are, what they’re doing and expressing, are constantly changing and often confounding. If these algorithms were being applied in a situation like analyzing surveillance footage, they’d be unreliable and—at least sometimes—totally out of sync with what a human would be perceiving.
Paglen: I also made a series of images of clouds. You’re seeing the cloud in a photograph I made, but you’re also seeing the cloud as it’s being seen through computer vision algorithms—including some used by drone and missile systems, facial recognition systems, and self-driving cars. It’s kind of a contemporary take on Stieglitz’s photographs of clouds. When you think about computer vision, what it’s essentially doing is taking an image, or some kind of visual sensory input, and creating a mathematical abstraction out of it.
Miller: A critic writing for Forbes, Jonathon Keats, said that you are to artificial intelligence “what Upton Sinclair was to meatpacking.” It’s a great comparison.
Paglen: Well, that’s a very high compliment, because it took me a long time to develop an understanding of how these tools work, and a feeling for it, and then to find language to talk about it. It’s a different paradigm, a fundamentally different way of thinking about images than I was taught in art school.

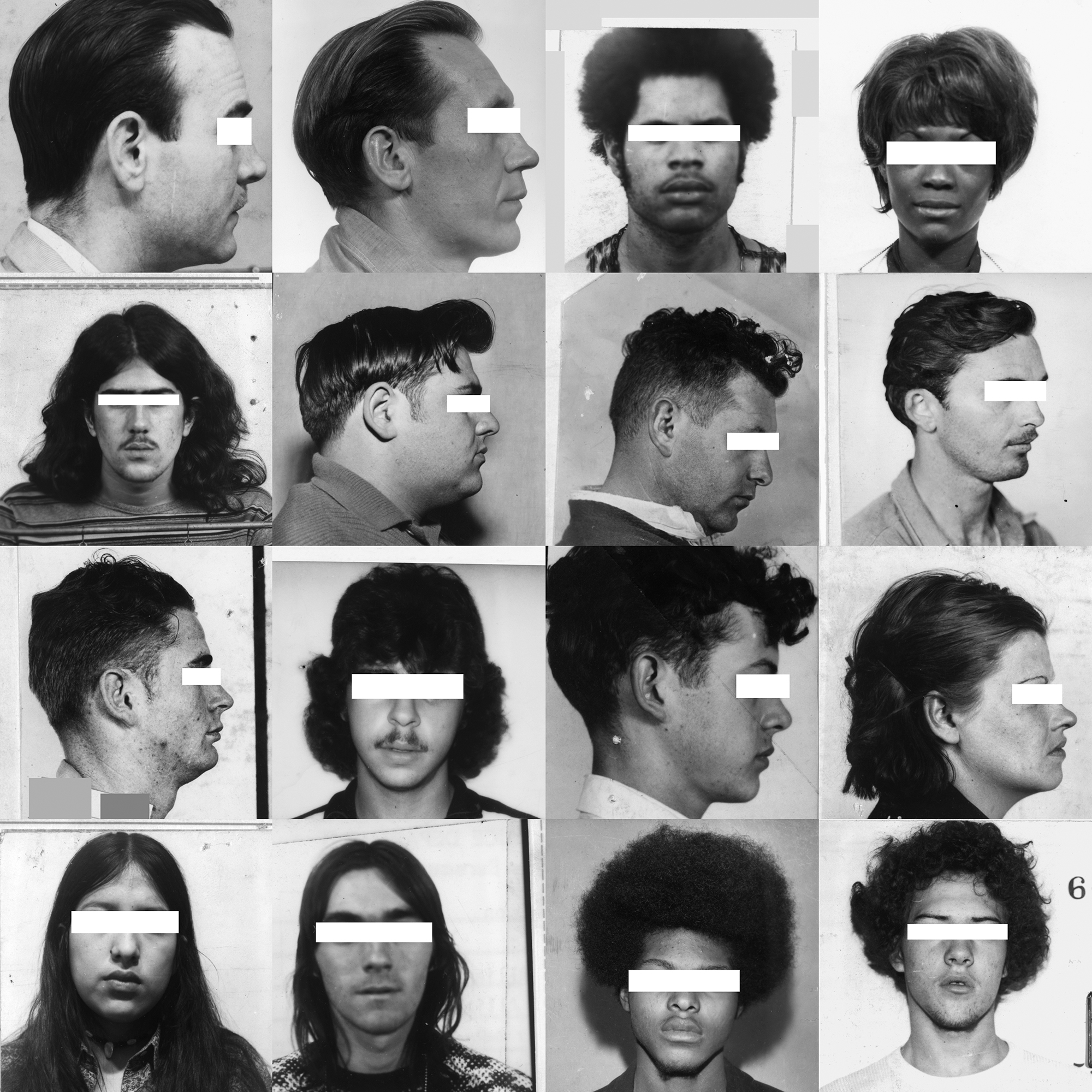
Miller: Your work on training sets has exposed the perils of simplistic image labeling that equates picture with thing, type, or identity. ImageNet Roulette (2019), for example, demonstrates that the prevailing attitudes underlying our foundational facial image recognition tools are equal parts absurd, crass, stereotypical, racist, and misogynist, not to mention culturally and historically bound.
Paglen: ImageNet is the most widely used dataset in computer vision research, created between 2009 and 2011. The people who created it said they wanted to make a database of “the entire world of objects.” So how do you do that? They took WordNet, a specific kind of dictionary where synonyms are clustered according to concept, in a hierarchical structure, under high-level categories like plant, person, and artifact. They only kept the nouns; the theory was that a noun is an object you can take a picture of. Each synonym became a slot. Then they scraped the whole internet, pulling in as many images as they could, and hired clickworkers to organize those images into the slots. In other words, the process required workers to decide what each image meant, and label it from a pre-given classification scheme.
It was kind of quaint, in retrospect. They were thinking, It’s so big, who could possibly ever look at the whole thing? Well, you can look at twenty thousand words, and the images to which they’ve been correlated, in an afternoon. The fundamental approach is terrible. There are tons of misogynistic nouns, tons of racist nouns, cruel nouns—nouns that are at once abstract and terrible. There are also plenty of nouns that aren’t visual at all.
When projects like ImageNet Roulette came out, and other people started looking at these datasets and realizing how terrible they were, the industry response was: “Let’s just remove anything that could be controversial.” There was no fundamental rethinking of the architecture, or of that relationship between images and concepts.

Aperture Magazine Subscription
0.00

Miller: In an article coauthored with Kate Crawford, you wrote: “Images are remarkably slippery things, laden with multiple potential meanings, irresolvable questions, and contradictions. Entire subfields of philosophy, art history, and media theory are dedicated to teasing out all the nuances of the unstable relationship between images and meanings.” And yet here we are: subject to vastly powerful systems built by people who never seem to question the relationship between representation and reality, pictures and meaning.
Paglen: Where these correspondences are most obviously “useful” is in industrial processes and in policing. Computer vision systems built to monitor truck drivers are a good example. Right now, you’re seeing the truck drivers as the canaries in coal mines, in terms of what the future AI-assisted labor surveillance looks like. The company that owns the truck will install a smart camera in the truck that watches the driver, and if—according to an algorithm—the driver is smoking a cigarette, or eating, or takes their eyes off the road, or looks drowsy, they’ll get pinged. They’ll get fined, or their supervisors will be contacted. So there’s an automation of surveillance of this kind of labor.
You’re seeing something similar emerge now in normal cars, where insurance companies want data about how you’re driving, and to modulate your insurance premiums in real time based on how a computer vision system is evaluating your driving. Philosophically and morally, there are huge problems with this way of thinking about images. But if you want to extract value from a domestic or previously private space, these tools are very good at doing that.
“Artificial intelligence” doesn’t really mean anything. It’s a term that lends itself to mystification.
Miller: I think you’re saying that the work of extracting value from labeled images via artificial intelligence gets more sophisticated—but the approach to images themselves is not getting any more nuanced.
Paglen: I want to say something more precise, which is that literalness and the economics of extraction go hand in hand. If a company wants to extract value by putting a computer vision system in your kitchen to watch what you eat, what they don’t want to do is say, “Oh, the meaning of that food is variable . . . it’s all contextual, it’s relational.” What they want to be able to say is, “You ate the doughnut, your health insurance is going to go up.” So the quantification is part of the process of value extraction. The quantification of an image is where I think we agree there’s a massive philosophical problem, as well as a human rights problem. But that moment of quantification is the precondition for being able to extract value. These very rigid ways of seeing are a feature of the system, not a bug.
Miller: You regularly talk to people who work in AI, and specifically in the area of training sets for machine learning. What do they say when you raise the idea that images don’t have transparent, consistent meanings?
Paglen: It’s very rare, I’ve found, among people who come from an engineering background, or mathematics or computer science, to be able to conceptualize the world in a way that does not reduce it to computation. I have yet to have a nuanced discussion with somebody coming out of that technical background who is able to really engage with the idea that there is a deep, irresolvable philosophical problem here—one that is not just a thought experiment but that has genuine and often deadly consequences for real life.

Miller: Your work is dedicated, in large part, to exposing the infrastructures of analytical and predictive systems that we can’t see. Do you think that the recent shift in popular attention to generative AI—this widely available power to order up an image, or generate text—is a distraction from the underlying technologies? Or does it inspire you to pursue a new set of questions?
Paglen: The work I’ve done in response to the generative turn doesn’t use AI machine vision at all. I’m thinking about the history and practice of the manipulation of perception, in relation to media that’s increasingly self-optimized to produce a specific response in an individual—to make them believe something that you want them to believe, to make them perceive something that you want them to perceive, or to make them do what you want them to do.
I’m looking at things like CIA mind-control experiments, stage magic, military psychological operations. These are all examples of some kind of authority using techniques that take advantage of the quirks in your perception, in order to make you perceive the world in a particular way. That is not only what generative AI is doing under the hood, so to speak, but where I think it will go culturally.
Miller: What accounts for your shift in approach? Much of the work you did about computer vision was openly didactic, whereas the more recent work on psyops and mind control seems more oblique.
Paglen: I think about my history as an artist as characterized by different ways of looking at technology. One mode is looking at infrastructure: Let’s go look at data centers, undersea cables, spy satellites in the sky. Let’s see all the stuff around us that is part of planetary computation systems, or surveillance systems, or sensing systems. In mode two, I’m looking at things that are also looking at me. How do these machines see? That encompasses computer vision, AI, that sort of thing.
I think the third phase I’m heading into now is: How are they currently able to make us see things, and images, that we didn’t see before? What are the politics of that? In other words, how did these technologies that are able to see us create the possibility of a media landscape in which not only are we being surveilled, but that surveillance is being used to create new kinds of visual culture for humans, in order to extract value from us?
Miller: Could you describe one of the newer works that addresses the media you’re describing—media that is tailored to make us see, or react to, or believe something?
Paglen: One of the central works so far is a video installation of a guy talking, Doty (2023). The guy is Richard Doty, who did psyops for the Air Force in the 1970s and 1980s. He talks about the technique and the trainings: “This is how you conduct influence operations.” “These are the elements that you need to make a good one.” He’s breaking down how you do it. Then he talks about influence operations that he ran against different people, mostly using UFOs as a kind of mimetic device to get people to see things or to believe things that he wanted them to believe. But then, there’s also a flip in the film, where he says, “Yes, I created a ton of disinformation and ran a bunch of psyops using the UFO as a mimetic device. But also, UFOs are real. And I’m going to tell you about them now.”
I find this guy’s tactics a, for lack of a better word, mind fuck. I also think it points to an emerging media environment where the distinction between reality and unreality, or between hallucination and fidelity, is irrelevant.
I have a new project of UFO photography, which is something I’ve always been super interested in. I often think about UFO photography as the paradigm of photography. Something like, all photos are UFO photos. It’s very much in line with the recent work on psyops.

All images courtesy the artist; Altman Siegel, San Francisco; and Pace Gallery
Miller: Photography historians like me, of course, love to point out that it’s always been possible to manipulate or stage or alter an image to present a deceptive or partisan view of reality. But with generative AI, we’re way beyond Stalin removing his political rivals from official photographs, both in terms of reach and potential consequences. How do you think we might deal with the problem of propagandistic deep fakes, for example, without reinforcing the notion that a real photograph is, or ever was, a necessarily truthful witness?
Paglen: As people who think about photographs, we know that they’re staged, they’re decontextualized, et cetera. However, I think that both of us would say it is a good thing that we got the images from Abu Ghraib, for example, in the sense that they did political work. Or at least, they prompted discussion by making something visible. Even though photographs don’t tell the Truth, they have a kind of aesthetics of truth that can take you pretty far in terms of putting things on a cultural agenda.
AI breaks the idea that somebody took the picture. I worry that even though we’re suspicious of concepts like indexicality, they still do cultural work in terms of how we read photographs collectively. When that breaks, I don’t know what happens. It does break a shared reality, which didn’t exist in the first place, that was always manufactured. That’s a depressing question to have to ask: Is manufacturing consent the precondition of a certain kind of democracy?
Miller: Is this the end of photography as we knew it then?
Paglen: Well, I think how we understand photography is more important than ever. People who study photographs or make photographs or work with photographs are highly relevant to a world in which everything is photography. I think about self-driving cars as photography and spy satellites and drones as photography. I think about any facial recognition system as photography. Photography is the paradigm of human-technology interfaces, and at this point, it’s basically synonymous with a huge amount of the infrastructure we interact with. People who think critically about photographs have a great deal to contribute, in terms of trying to conceive of and implement the kind of world that we want to live in, because the world is increasingly hard to distinguish from photography.
This article originally appeared in Aperture No. 257, “Image Worlds to Come: Photography & AI.”






